|
1.
|
Cultivating Pluralism In Algorithmic Monoculture: The Community Alignment Dataset abstract
Lily H Zhang, Smitha Milli, Karen Long Jusko, Jonathan Smith, Brandon Amos, Wassim Bouaziz, Jack Kussman, Manon Revel, Lisa Titus, Bhaktipriya Radharapu, Jane Yu, Vidya Sarma, Kristopher Rose, and Maximilian Nickel
ICLR 2026
How can large language models (LLMs) serve users with varying preferences that may conflict across cultural, political, or other dimensions? To advance this challenge, this paper establishes four key results. First, we demonstrate, through a large-scale multilingual human study with representative samples from five countries (N=15,000), that humans exhibit significantly more variation in preferences than the responses of 21 state-of-the-art LLMs. Second, we show that existing methods for preference dataset collection are insufficient for learning the diversity of human preferences even along two of the most salient dimensions of variability in global values, due to the underlying homogeneity of candidate responses. Third, we argue that this motivates the need for negatively-correlated sampling when generating candidate sets, and we show that simple prompt-based techniques for doing so significantly enhance the performance of alignment methods in learning heterogeneous preferences. Fourth, based on this novel candidate sampling approach, we collect and open-source Community Alignment, the largest and most representative multilingual and multi-turn preference dataset to date, featuring almost 200,000 comparisons from annotators spanning five countries. We hope that the Community Alignment dataset will be a valuable resource for improving the effectiveness of LLMs for a diverse global population.
|
|
2.
|
The Surprising Difficulty of Search in Model-Based Reinforcement Learning abstract
Wei-Di Chang, Mikael Henaff, Brandon Amos, Gregory Dudek, and Scott Fujimoto
ICML 2026
This paper investigates search in model-based reinforcement learning (RL). Conventional wisdom holds that long-term predictions and compounding errors are the primary obstacles for model-based RL. We challenge this view, showing that search is not a plug-and-play replacement for a learned policy. Surprisingly, we find that search can harm performance even when the model is highly accurate. Instead, we show that mitigating distribution shift matters more than improving model or value function accuracy. Building on this insight, we identify key techniques for enabling effective search, achieving state-of-the-art performance across multiple popular benchmark domains.
|
|
3.
|
Safety Alignment of LMs via Non-cooperative Games abstractcode
Anselm Paulus, Ilia Kulikov, Brandon Amos, Rémi Munos, Ivan Evtimov, Kamalika Chaudhuri, and Arman Zharmagambetov
ICML 2026
Ensuring the safety of language models (LMs) while
maintaining their usefulness remains a critical
challenge in AI alignment. Current approaches rely
on sequential adversarial training: generating
adversarial prompts and fine-tuning LMs to defend
against them. We introduce a different paradigm:
framing safety alignment as a non-zero-sum game
between an Attacker LM and a Defender LM trained
jointly via online reinforcement learning. Each LM
continuously adapts to the other’s evolving
strategies, driving iterative improvement. Our
method uses a preference-based reward signal derived
from pairwise comparisons instead of point-wise
scores, providing more robust supervision and
potentially reducing reward hacking. Our RL recipe, AdvGame, shifts the Pareto frontier of safety and
utility, yielding a Defender LM that is
simultaneously more helpful and more resilient to
adversarial attacks. In addition, the resulting
Attacker LM converges into a strong, general-purpose
red-teaming agent that can be directly deployed to
probe arbitrary target models.
|
|
4.
|
A Fully First-Order Layer for Differentiable Optimization abstractcode
Zihao Zhao, Kai-Chia Mo, Shing-Hei Ho, Brandon Amos, and Kai Wang
ICML 2026
Differentiable optimization layers enable learning systems to make decisions by solving embedded optimization problems. However, computing gradients via implicit differentiation requires solving a linear system with Hessian terms, which is both compute- and memory-intensive. To address this challenge, we propose a novel algorithm that computes the gradient using only first-order information. The key insight is to rewrite the differentiable optimization as a bilevel optimization problem and leverage recent advances in bilevel methods. Specifically, we introduce an active-set Lagrangian hypergradient oracle that avoids Hessian evaluations and provides finite-time, non-asymptotic approximation guarantees. We show that an approximate hypergradient can be computed using only first-order information in about constant time (up to logarithmic factors), leading to an overall complexity on the order of δ⁻¹ε⁻³ for constrained bilevel optimization, which matches the best known rate for non-smooth non-convex optimization. Furthermore, we release an open-source Python library that can be easily adapted from existing solvers.
|
|
5.
|
Score Function Gradient Estimation to Widen the Applicability of Decision-Focused Learning abstract
Mattia Silvestri, Senne Berden, Jayanta Mandi, Ali İrfan Mahmutoğulları, Brandon Amos, Tias Guns, and Michele Lombardi
JAIR 2026
Many real-world optimization problems contain parameters that are unknown before deployment time, either due to stochasticity or to lack of information (e.g., demand or travel times in delivery problems). A common strategy in such cases is to estimate said parameters via machine learning (ML) models trained to minimize the prediction error, which however is not necessarily aligned with the downstream task-level error. The decision-focused learning (DFL) paradigm overcomes this limitation by training to directly minimize a task loss, e.g. regret. Since the latter has non-informative gradients for combinatorial problems, state-of-the-art DFL methods introduce surrogates and approximations that enable training. But these methods exploit specific assumptions about the problem structures (e.g., convex or linear problems, unknown parameters only in the objective function). We propose an alternative method that makes no such assumptions, it combines stochastic smoothing with score function gradient estimation which works on any task loss. This opens up the use of DFL methods to nonlinear objectives, uncertain parameters in the problem constraints, and even two-stage stochastic optimization. Experiments show that it typically requires more epochs, but that it is on par with specialized methods and performs especially well for the difficult case of problems with uncertainty in the constraints, in terms of solution quality, scalability, or both.
|
|
6.
|
Social Choice Foundations for Simulation-Augmented Generation abstract
Sonja Kraiczy, Smitha Milli, Ratip Emin Berker, Avinandan Bose, Brandon Amos, Jamelle Watson-Daniels, Maximilian Nickel, Edith Elkind, and Ariel D. Procaccia
ICML AI4GOOD Workshop 2026
Users increasingly turn to AI systems for normative assistance—guidance on what one ought to do or think—yet models are often opaque about whose viewpoints they represent. A promising approach is simulation-augmented generation (SAGE), which involves querying generative simulations of individuals in a target population at inference time, soliciting their open-ended judgments, and synthesizing them into a response while transparently reporting whose viewpoints are reflected. However, inference-time simulation raises acute scalability constraints. Since the key benefit of simulation is improved representativeness, the core challenge is scaling simulation without sacrificing representation. We introduce the first formalization of this problem, grounded in proportional clustering concepts from social choice theory. We prove that to represent a population of m humans, we need only create n≪m simulations of them, and need only dynamically query k≪n of those simulations at inference time, while still maintaining approximate proportional representation guarantees for the full population. We empirically validate that our inference-time algorithm yields better representation–efficiency trade-offs than baseline approaches.
|
|
7.
|
Online Intrinsic Rewards for Decision Making Agents from Large Language Model Feedback abstractcode
Qinqing Zheng, Mikael Henaff, Amy Zhang, Aditya Grover, and Brandon Amos
RLC 2025
Automatically synthesizing dense rewards from natural language
descriptions is a promising paradigm in
reinforcement learning (RL), with applications to
sparse reward problems, open-ended exploration, and
hierarchical skill design. Recent works have made
promising steps by exploiting the prior knowledge of
large language models (LLMs). However, these
approaches suffer from important limitations: they
are either not scalable to problems requiring
billions of environment samples; or are limited to
reward functions expressible by compact code, which
may require source code and have difficulty
capturing nuanced semantics; or require a diverse
offline dataset, which may not exist or be
impossible to collect. In this work, we address
these limitations through a combination of
algorithmic and systems-level contributions. We
propose ONI, a distributed architecture that
simultaneously learns an RL policy and an intrinsic
reward function using LLM feedback. Our approach
annotates the agent’s collected experience via an
asynchronous LLM server, which is then distilled
into an intrinsic reward model. We explore a range
of algorithmic choices for reward modeling with
varying complexity, including hashing, classification, and ranking models. By studying
their relative tradeoffs, we shed light on questions
regarding intrinsic reward design for sparse reward
problems. Our approach achieves state-of-the-art
performance across a range of challenging, sparse
reward tasks from the NetHack Learning Environment
in a simple unified process, solely using the
agent’s gathered experience, without requiring
external datasets nor source code.
|
|
8.
|
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs abstractcodeslides
Anselm Paulus*, Arman Zharmagambetov*, Chuan Guo, Brandon Amos†, and Yuandong Tian†
ICML 2025
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming.
On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the target LLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, approximately 800 times faster than existing optimization-based approaches.
We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the target LLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the target LLM is lured to give a harmful response. Experimental results on popular open source target LLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by Advprompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
|
|
9.
|
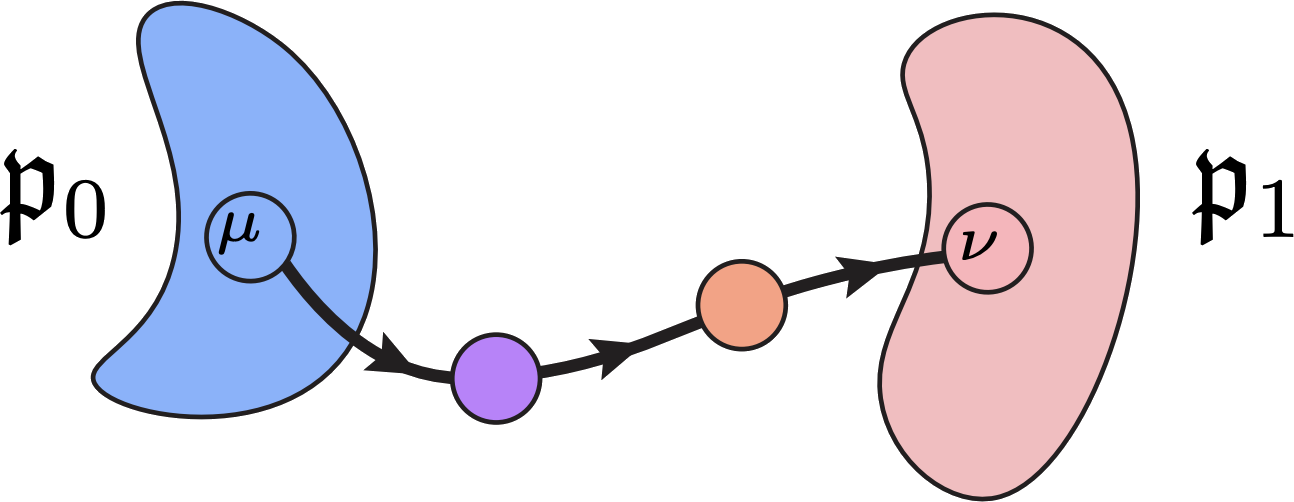 Wasserstein Flow Matching: Generative modeling over families of distributions abstractcode
Wasserstein Flow Matching: Generative modeling over families of distributions abstractcode
Doron Haviv, Aram-Alexandre Pooladian, Dana Pe'er, and Brandon Amos
ICML 2025
Generative modeling typically concerns the transport of a single
source distribution to a single target distribution
by learning (i.e., regressing onto) simple
probability flows. However, in modern data-driven
fields such as computer graphics and single-cell
genomics, samples (say, point-clouds) from datasets
can themselves be viewed as distributions (as, say, discrete measures). In these settings, the standard
generative modeling paradigm of flow matching would
ignore the relevant geometry of the samples. To
remedy this, we propose Wasserstein flow
matching (WFM), which appropriately lifts flow
matching onto families of distributions by appealing
to the Riemannian nature of the Wasserstein
geometry. Our algorithm leverages theoretical and
computational advances in (entropic) optimal
transport, as well as the attention mechanism in our
neural network architecture. We present two novel
algorithmic contributions. First, we demonstrate how
to perform generative modeling over Gaussian
distributions, where we generate representations of
granular cell states from single-cell genomics
data. Secondly, we show that WFM can learn flows
between high-dimensional and variable sized
point-clouds and synthesize cellular
microenvironments from spatial transcriptomics
datasets.
|
|
10.
|
Adjoint Sampling: Highly Scalable Diffusion Samplers via Adjoint Matching abstractcode
Aaron Havens, Benjamin Kurt Miller, Bing Yan, Carles Domingo-Enrich, Anuroop Sriram, Brandon Wood, Daniel Levine, Bin Hu, Brandon Amos, Brian Karrer, Xiang Fu, Guan-Horng Liu, and Ricky T. Q. Chen
ICML 2025
We introduce Adjoint Sampling, a highly scalable and efficient algorithm for learning diffusion processes that sample from unnormalized densities, or energy functions. It is the first on-policy approach that allows significantly more gradient updates than the number of energy evaluations and model samples, allowing us to scale to much larger problem settings than previously explored by similar methods. Our framework is theoretically grounded in stochastic optimal control and shares the same theoretical guarantees as Adjoint Matching, being able to train without the need for corrective measures that push samples towards the target distribution. We show how to incorporate key symmetries, as well as periodic boundary conditions, for modeling molecules in both cartesian and torsional coordinates. We demonstrate the effectiveness of our approach through extensive experiments on classical energy functions, and further scale up to neural network-based energy models where we perform amortized conformer generation across many molecular systems. To encourage further research in developing highly scalable sampling methods, we open source these challenging benchmarks, where successful methods can directly impact progress in computational chemistry.
|
|
11.
|
Exact Byte-Level Probabilities from Tokenized Language Models for FIM-Tasks and Model Ensembles abstractcode
Buu Phan, Brandon Amos, Itai Gat, Marton Havasi, Matthew Muckley, and Karen Ullrich
ICLR 2025
Tokenization is associated with many poorly understood shortcomings in language models (LMs), yet remains an important component for long sequence scaling purposes. This work studies how tokenization impacts model performance by analyzing and comparing the stochastic behavior of tokenized models with their byte-level, or token-free, counterparts. We discover that, even when the two models are statistically equivalent, their predictive distributions over the next byte can be substantially different, a phenomenon we term as “tokenization bias”. To fully characterize this phenomenon, we introduce the Byte-Token Representation Lemma, a framework that establishes a mapping between the learned token distribution and its equivalent byte-level distribution. From this result, we develop a next-byte sampling algorithm that eliminates tokenization bias without requiring further training or optimization. In other words, this enables zero-shot conversion of tokenized LMs into statistically equivalent token-free ones. We demonstrate its broad applicability with two use cases: fill-in-the-middle (FIM) tasks and model ensembles. In FIM tasks where input prompts may terminate mid-token, leading to out-of-distribution tokenization, our method mitigates performance degradation and achieves an approximately 18% improvement in FIM coding benchmarks, consistently outperforming the standard token healing fix. For model ensembles where each model employs a distinct vocabulary, our approach enables seamless integration, resulting in improved performance (up to 3.7%) over individual models across various standard baselines in reasoning, knowledge, and coding.
|
|
12.
|
 Meta Flow Matching: Integrating Vector Fields on the Wasserstein Manifold abstractcode
Meta Flow Matching: Integrating Vector Fields on the Wasserstein Manifold abstractcode
Lazar Atanackovic, Xi Zhang, Brandon Amos, Mathieu Blanchette, Leo J Lee, Yoshua Bengio, Alexander Tong, and Kirill Neklyudov
ICLR 2025
|
|
13.
|
AdvPrefix: An Objective for Nuanced LLM Jailbreaks abstract
Sicheng Zhu, Brandon Amos, Yuandong Tian, Chuan Guo, and Ivan Evtimov
NeurIPS 2025
Many jailbreak attacks on large language models (LLMs) rely on a
common objective: making the model respond with the
prefix “Sure, here is (harmful request)”. While
straightforward, this objective has two limitations:
limited control over model behaviors, often
resulting in incomplete or unrealistic responses, and a rigid format that hinders optimization. To
address these limitations, we introduce AdvPrefix, a
new prefix-forcing objective that enables more
nuanced control over model behavior while being easy
to optimize. Our objective leverages model-dependent
prefixes, automatically selected based on two
criteria: high prefilling attack success rates and
low negative log-likelihood. It can further simplify
optimization by using multiple prefixes for a single
user request. AdvPrefix can integrate seamlessly
into existing jailbreak attacks to improve their
performance for free. For example, simply replacing
GCG attack’s target prefixes with ours on Llama-3
improves nuanced attack success rates from 14% to
80%, suggesting that current alignment struggles to
generalize to unseen prefixes. Our work demonstrates
the importance of jailbreak objectives in achieving
nuanced jailbreaks.
|
|
14.
|
AlgoTune: Can Language Models Speed Up General-Purpose Numerical Programs? abstractcode
Ori Press, Brandon Amos, Haoyu Zhao, Yikai Wu, Samuel K. Ainsworth, Dominik Krupke, Patrick Kidger, Touqir Sajed, Bartolomeo Stellato, Jisun Park, Nathanael Bosch, Eli Meril, Albert Steppi, Arman Zharmagambetov, Fangzhao Zhang, David Pérez-Piñeiro, Alberto Mercurio, Ni Zhan, Talor Abramovich, Kilian Lieret, Hanlin Zhang, Shirley Huang, Matthias Bethge, and Ofir Press
NeurIPS Datasets and Benchmarks Track 2025
Despite progress in language model (LM) capabilities, evaluations
have thus far focused on models’ performance on
tasks that humans have previously solved, including
in programming (Jimenez et al., 2024) and
mathematics (Glazer et al., 2024). We therefore
propose testing models’ ability to design and
implement algorithms in an open-ended benchmark: We
task LMs with writing code that efficiently solves
computationally challenging problems in computer
science, physics, and mathematics. Our AlgoTune
benchmark consists of 155 coding tasks collected
from domain experts and a framework for validating
and timing LM-synthesized solution code, which is
compared to reference implementations from popular
opensource packages. In addition, we develop a
baseline LM agent, AlgoTuner, and evaluate its
performance across a suite of frontier
models. AlgoTuner achieves an average 1.76x speedup
against our reference solvers, which use libraries
such as SciPy, sk-learn and CVXPY. However, we find
that current models fail to discover algorithmic
innovations, instead preferring surface-level
optimizations. We hope that AlgoTune catalyzes the
development of LM agents exhibiting creative problem
solving beyond state-of-the-art human performance.
|
|
15.
|
BaNEL: Exploration Posteriors for Generative Modeling Using Only Negative Rewards abstract
Sangyun Lee, Brandon Amos, and Giulia Fanti
arXiv 2025
Today’s generative models thrive with large amounts of supervised data and informative reward functions characterizing the quality of the generation. They work under the assumptions that the supervised data provides knowledge to pre-train the model, and the reward function provides dense information about how to further improve the generation quality and correctness. However, in the hardest instances of important problems, two problems arise: (1) the base generative model attains a near-zero reward signal, and (2) calls to the reward oracle are expensive. This setting poses a fundamentally different learning challenge than standard reward-based post-training. To address this, we propose BaNEL (Bayesian Negative Evidence Learning), an algorithm that post-trains the model using failed attempts only, while minimizing the number of reward evaluations (NREs). Our method is based on the idea that the problem of learning regularities underlying failures can be cast as another, in-loop generative modeling problem. We then leverage this model to assess whether new data resembles previously seen failures and steer the generation away from them. We show that BaNEL can improve model performance without observing a single successful sample on several sparse-reward tasks, outperforming existing novelty-bonus approaches by up to several orders of magnitude in success rate, while using fewer reward evaluations.
|
|
16.
|
 Neural Optimal Transport with Lagrangian Costs abstractcode
Neural Optimal Transport with Lagrangian Costs abstractcode
Aram-Alexandre Pooladian, Carles Domingo-Enrich, Ricky T. Q. Chen, and Brandon Amos
UAI 2024
We investigate the optimal transport problem between probability measures when the underlying cost function is understood to satisfy a least action principle, also known as a Lagrangian cost. These generalizations are useful when connecting observations from a physical system, where the transport dynamics are influenced by the geometry of the system, such as obstacles, (e.g., incorporating barrier functions in the Lagrangian) and allows practitioners to incorporate a priori knowledge of the underlying system such as non-Euclidean geometries (e.g., paths must be circular). Our contributions are of computational interest, where we demonstrate the ability to efficiently compute geodesics and amortize spline-based paths, which has not been done before, even in low dimensional problems. Unlike prior work, we also output the resulting Lagrangian optimal transport map without requiring an ODE solver. We demonstrate the effectiveness of our formulation on low-dimensional examples taken from prior work.
|
|
17.
|
Learning to Warm-Start Fixed-Point Optimization Algorithms abstractcode
Rajiv Sambharya, Georgina Hall, Brandon Amos, and Bartolomeo Stellato
JMLR 2024
We introduce a machine-learning framework to warm-start fixed-point optimization algorithms. Our architecture consists of a neural network mapping problem parameters to warm starts, followed by a predefined number of fixed-point iterations. We propose two loss functions designed to either minimize the fixed-point residual or the distance to a ground truth solution. In this way, the neural network predicts warm starts with the end-to-end goal of minimizing the downstream loss. An important feature of our architecture is its flexibility, in that it can predict a warm start for fixed-point algorithms run for any number of steps, without being limited to the number of steps it has been trained on. We provide PAC-Bayes generalization bounds on unseen data for common classes of fixed-point operators: contractive, linearly convergent, and averaged. Applying this framework to well-known applications in control, statistics, and signal processing, we observe a significant reduction in the number of iterations and solution time required to solve these problems, through learned warm starts.
|
|
18.
|
Unlocking Tokens as Data Points for Generalization Bounds on Larger Language Models abstractcode
Sanae Lotfi, Yilun Kuang, Marc Anton Finzi, Brandon Amos, Micah Goldblum, and Andrew Gordon Wilson
NeurIPS 2024
Large language models (LLMs) with billions of parameters excel at
predicting the next token in a sequence. Recent work
computes non-vacuous compression-based
generalization bounds for LLMs, but these bounds are
vacuous for large models at the billion-parameter
scale. Moreover, these bounds are obtained through
restrictive compression techniques, bounding
compressed models that generate low-quality
text. Additionally, the tightness of these existing
bounds depends on the number of IID documents in a
training set rather than the much larger number of
non-IID constituent tokens, leaving untapped
potential for tighter bounds. In this work, we
instead use properties of martingales to derive
generalization bounds that benefit from the vast
number of tokens in LLM training sets. Since a
dataset contains far more tokens than documents, our
generalization bounds not only tolerate but actually
benefit from far less restrictive compression
schemes. With Monarch matrices, Kronecker
factorizations, and post-training quantization, we
achieve non-vacuous generalization bounds for LLMs
as large as LLaMA2-70B. Unlike previous approaches, our work achieves the first non-vacuous bounds for
models that are deployed in practice and generate
high-quality text.
|
|
19.
|
Stochastic Optimal Control Matching abstractcode
Carles Domingo-Enrich, Jiequn Han, Brandon Amos, Joan Bruna, and Ricky T. Q. Chen
NeurIPS 2024
Stochastic optimal control, which has the goal of driving the behavior of noisy systems, is broadly applicable in science, engineering and artificial intelligence. Our work introduces Stochastic Optimal Control Matching (SOCM), a novel Iterative Diffusion Optimization (IDO) technique for stochastic optimal control that stems from the same philosophy as the conditional score matching loss for diffusion models. That is, the control is learned via a least squares problem by trying to fit a matching vector field. The training loss, which is closely connected to the cross-entropy loss, is optimized with respect to both the control function and a family of reparameterization matrices which appear in the matching vector field. The optimization with respect to the reparameterization matrices aims at minimizing the variance of the matching vector field. Experimentally, our algorithm achieves lower error than all the existing IDO techniques for stochastic optimal control for four different control settings. The key idea underlying SOCM is the path-wise reparameterization trick, a novel technique that is of independent interest, e.g., for generative modeling.
|
|
20.
|
To the Globe (TTG): Towards Language-Driven Guaranteed Travel Planning abstract
Da JU, Song Jiang, Andrew Cohen, Aaron Foss, Sasha Mitts, Arman Zharmagambetov, Brandon Amos, Xian Li, Justine T Kao, Maryam Fazel-Zarandi, and Yuandong Tian
EMNLP Demo 2024
Travel planning is a challenging and time-consuming task that aims to find an itinerary which satisfies multiple, interdependent constraints regarding flights, accommodations, attractions, and other travel arrangements. In this paper, we propose To the Globe (TTG), a real-time demo system that takes natural language requests from users, translates it to symbolic form via a fine-tuned Large Language Model, and produces optimal travel itineraries with Mixed Integer Linear Programming solvers. The overall system takes ~5 seconds to reply to the user request with guaranteed itineraries. To train TTG, we develop a synthetic data pipeline that generates user requests, flight and hotel information in symbolic form without human annotations, based on the statistics of real-world datasets, and fine-tune an LLM to translate NL user requests to their symbolic form, which is sent to the symbolic solver to compute optimal itineraries. Our NL-symbolic translation achieves ~91% exact match in a backtranslation metric (i.e., whether the estimated symbolic form of generated natural language matches the groundtruth), and its returned itineraries have a ratio of 0.979 compared to the optimal cost of the ground truth user request. When evaluated by users, TTG achieves consistently high Net Promoter Scores (NPS) of 35-40% on generated itinerary.
|
|
21.
|
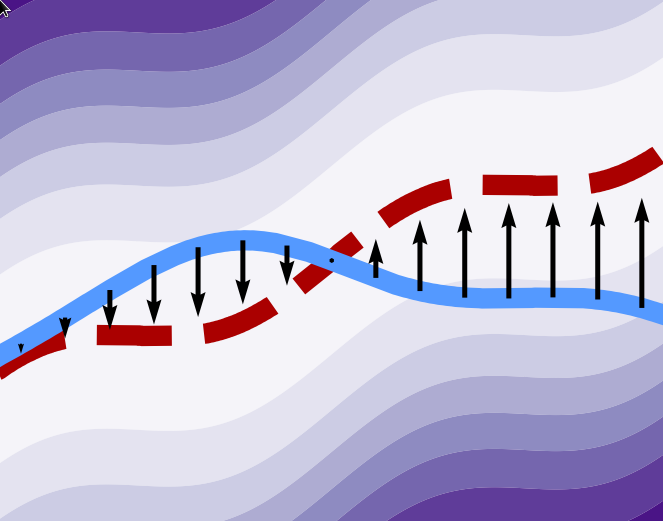 Tutorial on amortized optimization abstractcode
Tutorial on amortized optimization abstractcode
Brandon Amos
Foundations and Trends in Machine Learning 2023
Optimization is a ubiquitous modeling tool and is often deployed
in settings which repeatedly solve similar instances
of the same problem. Amortized optimization methods
use learning to predict the solutions to problems in
these settings, exploiting the shared structure
between similar problem instances. These methods
have been crucial in variational inference and
reinforcement learning and are capable of solving
optimization problems many orders of magnitudes
times faster than traditional optimization methods
that do not use amortization. This tutorial presents
an introduction to the amortized optimization
foundations behind these advancements and overviews
their applications in variational inference, sparse
coding, gradient-based meta-learning, control, reinforcement learning, convex optimization, optimal
transport, and deep equilibrium networks.
|
|
22.
|
 On amortizing convex conjugates for optimal transport abstractcode
On amortizing convex conjugates for optimal transport abstractcode
Brandon Amos
ICLR 2023
This paper focuses on computing the convex conjugate operation that
arises when solving Euclidean Wasserstein-2 optimal
transport problems. This conjugation, which is also
referred to as the Legendre-Fenchel conjugate or
c-transform, is considered difficult to compute and
in practice, Wasserstein-2 methods are limited by
not being able to exactly conjugate the dual
potentials in continuous space. I show that
combining amortized approximations to the conjugate
with a solver for fine-tuning is computationally
easy. This combination significantly improves the
quality of transport maps learned for the
Wasserstein-2 benchmark by Korotin et al. (2021) and
is able to model many 2-dimensional couplings and
flows considered in the literature.
|
|
23.
|
End-to-End Learning to Warm-Start for Real-Time Quadratic Optimization abstractcode
Rajiv Sambharya, Georgina Hall, Brandon Amos, and Bartolomeo Stellato
L4DC 2023
First-order methods are widely used to solve convex quadratic programs
(QPs) in real-time applications because of their low
per-iteration cost. However, they can suffer from
slow convergence to accurate solutions. In this
paper, we present a framework which learns an
effective warm-start for a popular first-order
method in real-time applications, Douglas-Rachford
(DR) splitting, across a family of parametric
QPs. This framework consists of two modules: a
feedforward neural network block, which takes as
input the parameters of the QP and outputs a
warm-start, and a block which performs a fixed
number of iterations of DR splitting from this
warm-start and outputs a candidate solution. A key
feature of our framework is its ability to do
end-to-end learning as we differentiate through the
DR iterations. To illustrate the effectiveness of
our method, we provide generalization bounds (based
on Rademacher complexity) that improve with the
number of training problems and number of iterations
simultaneously. We further apply our method to three
real-time applications and observe that, by learning
good warm-starts, we are able to significantly
reduce the number of iterations required to obtain
high-quality solutions.
|
|
24.
|
Meta Optimal Transport abstractcode
Brandon Amos, Samuel Cohen, Giulia Luise, and Ievgen Redko
ICML 2023
|
|
25.
|
Multisample Flow Matching: Straightening Flows with Minibatch Couplings abstract
Aram-Alexandre Pooladian, Heli Ben-Hamu, Carles Domingo-Enrich, Brandon Amos, Yaron Lipman, and Ricky T. Q. Chen
ICML 2023
Simulation-free methods for training continuous-time generative models
construct probability paths that go between noise
distributions and individual data samples. Recent
works, such as Flow Matching, derived paths that are
optimal for each data sample. However, these
algorithms rely on independent data and noise
samples, and do not exploit underlying structure in
the data distribution for constructing probability
paths. We propose Multisample Flow Matching, a more
general framework that uses non-trivial couplings
between data and noise samples while satisfying the
correct marginal constraints. At very small overhead
costs, this generalization allows us to (i) reduce
gradient variance during training, (ii) obtain
straighter flows for the learned vector field, which
allows us to generate high-quality samples using
fewer function evaluations, and (iii) obtain
transport maps with lower cost in high dimensions, which has applications beyond generative
modeling. Importantly, we do so in a completely
simulation-free manner with a simple minimization
objective. We show that our proposed methods improve
sample consistency on downsampled ImageNet data
sets, and lead to better low-cost sample generation.
|
|
26.
|
Semi-Supervised Offline Reinforcement Learning with Action-Free Trajectories abstractcode
Qinqing Zheng, Mikael Henaff, Brandon Amos, and Aditya Grover
ICML 2023
Natural agents can effectively learn from multiple data sources that
differ in size, quality, and types of
measurements. We study this heterogeneity in the
context of offline reinforcement learning (RL) by
introducing a new, practically motivated
semi-supervised setting. Here, an agent has access
to two sets of trajectories: labelled trajectories
containing state, action, reward triplets at every
timestep, along with unlabelled trajectories that
contain only state and reward information. For this
setting, we develop a simple meta-algorithmic
pipeline that learns an inverse-dynamics model on
the labelled data to obtain proxy-labels for the
unlabelled data, followed by the use of any offline
RL algorithm on the true and proxy-labelled
trajectories. Empirically, we find this simple
pipeline to be highly successful–on several D4RL
benchmarks, certain offline RL
algorithms can match the performance of variants
trained on a fully labeled dataset even when we
label only 10% trajectories from the low return
regime. Finally, we perform a large-scale controlled
empirical study investigating the interplay of
data-centric properties of the labelled and
unlabelled datasets, with algorithmic design choices
(e.g., inverse dynamics, offline RL algorithm) to
identify general trends and best practices for
training RL agents on semi-supervised offline
datasets.
|
|
27.
|
TaskMet: Task-Driven Metric Learning for Model Learning abstractcode
Dishank Bansal, Ricky T. Q. Chen, Mustafa Mukadam, and Brandon Amos
NeurIPS 2023
Deep learning models are often used with some downstream
task. Models solely trained to achieve accurate
predictions may struggle to perform well on
the desired downstream tasks. We propose using the
task’s loss to learn a metric which parameterizes a
loss to train the model.This approach does not alter
the optimal prediction model itself, but rather
changes the model learning to emphasize the
information important for the downstream task.This
enables us to achieve the best of both worlds:a
prediction model trained in the original prediction
space while also being valuable for the desired
downstream task.We validate our approach through
experiments conducted in two main settings: 1)
decision-focused model learning scenarios involving
portfolio optimization and budget allocation, and2)
reinforcement learning in noisy environments with
distracting states.
|
|
28.
|
Landscape Surrogate: Learning Decision Losses for Mathematical Optimization Under Partial Information abstractcode
Arman Zharmagambetov, Brandon Amos, Aaron Ferber, Taoan Huang, Bistra Dilkina, and Yuandong Tian
NeurIPS 2023
Recent works in learning-integrated optimization have shown promise in
settings where the optimization problem is only
partially observed or where general-purpose
optimizers perform poorly without expert tuning. By
learning an optimizer g to tackle these challenging
problems with f as the objective, the optimization
process can be substantially accelerated by
leveraging past experience. Training the optimizer
can be done with supervision from known optimal
solutions (not always available) or implicitly by
optimizing the compound function f ∘ g , but the
implicit approach is slow and challenging due to
frequent calls to the optimizer and sparse
gradients, particularly for combinatorial
solvers. To address these challenges, we propose
using a smooth and learnable Landscape Surrogate
M instead of composing f with g . This surrogate can be computed
faster than g, provides dense and smooth gradients
during training, can generalize to unseen
optimization problems, and is efficiently learned
via alternating optimization. We test our approach
on both synthetic problems and real-world problems, achieving comparable or superior objective values
compared to state-of-the-art baselines while
reducing the number of calls to g . Notably, our
approach outperforms existing methods for
computationally expensive high-dimensional problems.
|
|
29.
|
Koopman Constrained Policy Optimization: A Koopman operator theoretic method for differentiable optimal control in robotics abstractcode
Matthew Retchin, Brandon Amos, Steven Brunton, and Shuran Song
ICML Differentiable Almost Everything Workshop 2023
We introduce Koopman Constrained Policy Optimization (KCPO), combining implicitly differentiable model predictive
control with a deep Koopman autoencoder for robot
learning in unknown and nonlinear dynamical
systems. KCPO is a new policy optimization algorithm
that trains neural policies end-to-end with hard box
constraints on controls. Guaranteed satisfaction of
hard constraints helps ensure the performance and
safety of robots. We perform imitation learning with
KCPO to recover expert policies on the Simple
Pendulum, Cartpole Swing-Up, Reacher, and
Differential Drive environments, outperforming
baseline methods in generalizing to
out-of-distribution constraints in most environments
after training.
|
|
30.
|
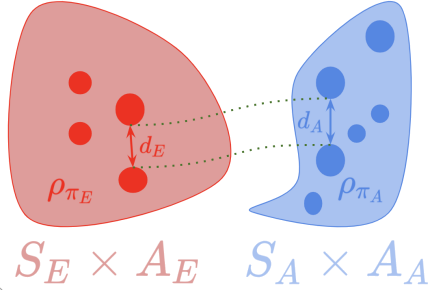 Cross-Domain Imitation Learning via Optimal Transport abstractcode
Cross-Domain Imitation Learning via Optimal Transport abstractcode
Arnaud Fickinger, Samuel Cohen, Stuart Russell, and Brandon Amos
ICLR 2022
Cross-domain imitation learning studies how to leverage expert
demonstrations of one agent to train an imitation
agent with a different embodiment or
morphology. Comparing trajectories and stationary
distributions between the expert and imitation
agents is challenging because they live on different
systems that may not even have the same
dimensionality. We propose Gromov-Wasserstein
Imitation Learning (GWIL), a method for cross-domain
imitation that uses the Gromov-Wasserstein distance
to align and compare states between the different
spaces of the agents. Our theory formally
characterizes the scenarios where GWIL preserves
optimality, revealing its possibilities and
limitations. We demonstrate the effectiveness of
GWIL in non-trivial continuous control domains
ranging from simple rigid transformation of the
expert domain to arbitrary transformation of the
state-action space.
|
|
31.
|
Matching Normalizing Flows and Probability Paths on Manifolds abstract
Heli Ben-Hamu*, Samuel Cohen*, Joey Bose, Brandon Amos, Aditya Grover, Maximilian Nickel, Ricky T. Q. Chen, and Yaron Lipman
ICML 2022
Continuous Normalizing Flows (CNFs) are a class of generative models
that transform a prior distribution to a model
distribution by solving an ordinary differential
equation (ODE). We propose to train CNFs on
manifolds by minimizing probability path divergence
(PPD), a novel family of divergences between the
probability density path generated by the CNF and a
target probability density path. PPD is formulated
using a logarithmic mass conservation formula which
is a linear first order partial differential
equation relating the log target probabilities and
the CNF’s defining vector field. PPD has several key
benefits over existing methods: it sidesteps the
need to solve an ODE per iteration, readily applies
to manifold data, scales to high dimensions, and is
compatible with a large family of target paths
interpolating pure noise and data in finite
time. Theoretically, PPD is shown to bound classical
probability divergences. Empirically, we show that
CNFs learned by minimizing PPD achieve
state-of-the-art results in likelihoods and sample
quality on existing low-dimensional manifold
benchmarks, and is the first example of a generative
model to scale to moderately high dimensional
manifolds.
|
|
32.
|
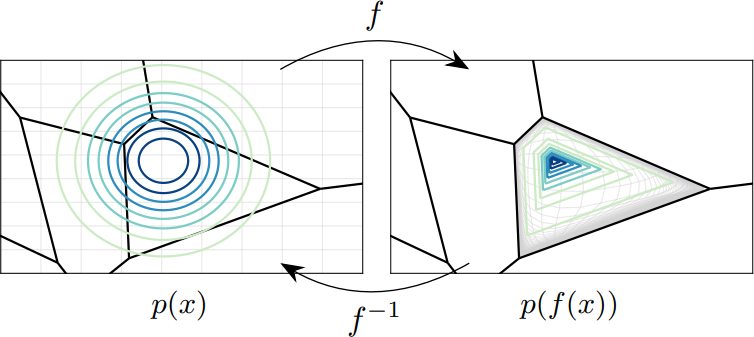 Semi-Discrete Normalizing Flows through Differentiable Tessellation abstract
Semi-Discrete Normalizing Flows through Differentiable Tessellation abstract
Ricky T. Q. Chen, Brandon Amos, and Maximilian Nickel
NeurIPS 2022
Mapping between discrete and continuous distributions is a difficult
task and many have had to resort to approximate or
heuristical approaches. We propose a
tessellation-based approach that directly learns
quantization boundaries on a continuous space, complete with exact likelihood evaluations. This is
done through constructing normalizing flows on
convex polytopes parameterized through a
differentiable Voronoi tessellation. Using a simple
homeomorphism with an efficient log determinant
Jacobian, we can then cheaply parameterize
distributions on convex polytopes.
We explore this approach in two application settings, mapping from
discrete to continuous and vice versa. Firstly, a
Voronoi dequantization allows automatically learning
quantization boundaries in a multidimensional
space. The location of boundaries and distances
between regions can encode useful structural
relations between the quantized discrete
values. Secondly, a Voronoi mixture model has
constant computation cost for likelihood evaluation
regardless of the number of mixture
components. Empirically, we show improvements over
existing methods across a range of structured data
modalities, and find that we can achieve a
significant gain from just adding Voronoi mixtures
to a baseline model.
|
|
33.
|
Theseus: A Library for Differentiable Nonlinear Optimization abstractcode
Luis Pineda, Taosha Fan, Maurizio Monge, Shobha Venkataraman, Paloma Sodhi, Ricky Chen, Joseph Ortiz, Daniel DeTone, Austin Wang, Stuart Anderson, Jing Dong, Brandon Amos, and Mustafa Mukadam
NeurIPS 2022
We present Theseus, an efficient application-agnostic open source
library for differentiable nonlinear least squares
(DNLS) optimization built on PyTorch, providing a
common framework for end-to-end structured learning
in robotics and vision. Existing DNLS
implementations are application specific and do not
always incorporate many ingredients important for
efficiency. Theseus is application-agnostic, as we
illustrate with several example applications that
are built using the same underlying differentiable
components, such as second-order optimizers, standard costs functions, and Lie groups. For
efficiency, Theseus incorporates support for sparse
solvers, automatic vectorization, batching, GPU
acceleration, and gradient computation with implicit
differentiation and direct loss minimization. We do
extensive performance evaluation in a set of
applications, demonstrating significant efficiency
gains and better scalability when these features are
incorporated.
|
|
34.
|
Nocturne: a driving benchmark for multi-agent learning abstractcode
Eugene Vinitsky, Nathan Lichtlé, Xiaomeng Yang, Brandon Amos, and Jakob Foerster
NeurIPS Datasets and Benchmarks Track 2022
We introduce Nocturne, a new 2D driving simulator for
investigating multi-agent coordination under partial
observability. The focus of Nocturne is to enable
research into inference and theory of mind in
real-world multi-agent settings without the
computational overhead of computer vision and
feature extraction from images. Agents in this
simulator only observe an obstructed view of the
scene, mimicking human visual sensing
constraints. Unlike existing benchmarks that are
bottlenecked by rendering human-like observations
directly using a camera input, Nocturne uses
efficient intersection methods to compute a
vectorized set of visible features in a C++
back-end, allowing the simulator to run at 2000+
steps-per-second. Using open-source trajectory and
map data, we construct a simulator to load and
replay arbitrary trajectories and scenes from
real-world driving data. Using this environment, we
benchmark reinforcement-learning and
imitation-learning agents and demonstrate that the
agents are quite far from human-level coordination
ability and deviate significantly from the expert
trajectories.
|
|
35.
|
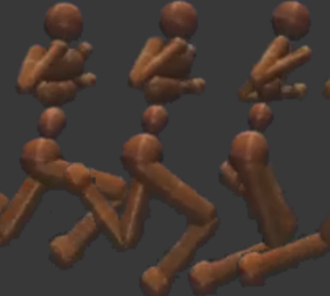 On the model-based stochastic value gradient for continuous reinforcement learning abstractcodeslides
On the model-based stochastic value gradient for continuous reinforcement learning abstractcodeslides
Brandon Amos, Samuel Stanton, Denis Yarats, and Andrew Gordon Wilson
L4DC 2021 (Oral)
Model-based reinforcement learning approaches add explicit domain
knowledge to agents in hopes of improving the
sample-efficiency in comparison to model-free
agents. However, in practice model-based methods are
unable to achieve the same asymptotic performance on
challenging continuous control tasks due to the
complexity of learning and controlling an explicit
world model. In this paper we investigate the
stochastic value gradient (SVG), which is a
well-known family of methods for controlling
continuous systems which includes model-based
approaches that distill a model-based value
expansion into a model-free policy. We consider a
variant of the model-based SVG that scales to larger
systems and uses 1) an entropy regularization to
help with exploration, 2) a learned deterministic
world model to improve the short-horizon value
estimate, and 3) a learned model-free value estimate
after the model’s rollout. This SVG variation
captures the model-free soft actor-critic method as
an instance when the model rollout horizon is zero, and otherwise uses short-horizon model rollouts to
improve the value estimate for the policy update. We
surpass the asymptotic performance of other
model-based methods on the proprioceptive MuJoCo
locomotion tasks from the OpenAI gym, including a
humanoid. We notably achieve these results with a
simple deterministic world model without requiring
an ensemble.
|
|
36.
|
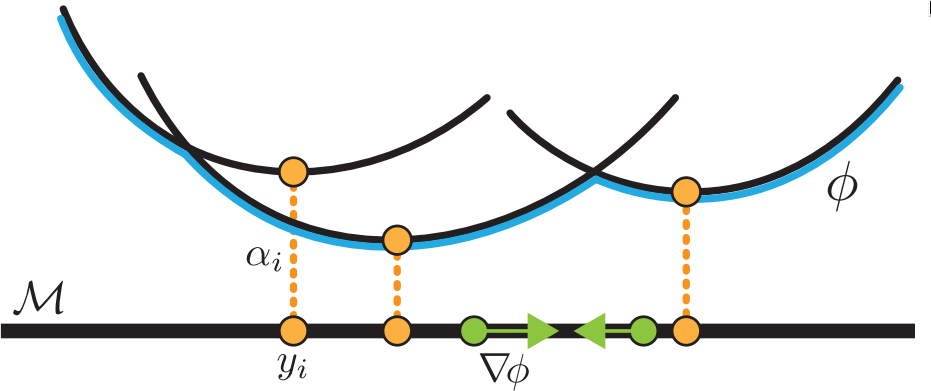 Riemannian Convex Potential Maps abstractcodeslides
Riemannian Convex Potential Maps abstractcodeslides
Samuel Cohen*, Brandon Amos*, and Yaron Lipman
ICML 2021
Modeling distributions on Riemannian manifolds is a crucial
component in understanding non-Euclidean data that
arises, e.g., in physics and geology. The budding
approaches in this space are limited by
representational and computational tradeoffs. We
propose and study a class of flows that uses convex
potentials from Riemannian optimal transport. These
are universal and can model distributions on any
compact Riemannian manifold without requiring domain
knowledge of the manifold to be integrated into the
architecture. We demonstrate that these flows can
model standard distributions on spheres, and tori, on synthetic and geological data.
|
|
37.
|
 CombOptNet: Fit the Right NP-Hard Problem by Learning Integer Programming Constraints abstractcode
CombOptNet: Fit the Right NP-Hard Problem by Learning Integer Programming Constraints abstractcode
Anselm Paulus, Michal Rolínek, Vít Musil, Brandon Amos, and Georg Martius
ICML 2021
Bridging logical and algorithmic reasoning with modern machine
learning techniques is a fundamental challenge with
potentially transformative impact. On the
algorithmic side, many NP-hard problems can be
expressed as integer programs, in which the
constraints play the role of their “combinatorial
specification”. In this work, we aim to integrate
integer programming solvers into neural network
architectures as layers capable of learning both the
cost terms and the constraints. The resulting
end-to-end trainable architectures jointly extract
features from raw data and solve a suitable
(learned) combinatorial problem with
state-of-the-art integer programming solvers. We
demonstrate the potential of such layers with an
extensive performance analysis on synthetic data and
with a demonstration on a competitive computer
vision keypoint matching benchmark.
|
|
38.
|
Scalable Online Planning via Reinforcement Learning Fine-Tuning abstract
Arnaud Fickinger, Hengyuan Hu, Brandon Amos, Stuart Russell, and Noam Brown
NeurIPS 2021
Lookahead search has been a critical component of recent AI successes, such as in the games of chess, go, and
poker. However, the search methods used in these
games, and in many other settings, are
tabular. Tabular search methods do not scale well
with the size of the search space, and this problem
is exacerbated by stochasticity and partial
observability. In this work we replace tabular
search with online model-based fine-tuning of a
policy neural network via reinforcement learning, and show that this approach outperforms
state-of-the-art search algorithms in benchmark
settings. In particular, we use our search algorithm
to achieve a new state-of-the-art result in
self-play Hanabi, and show the generality of our
algorithm by also showing that it outperforms
tabular search in the Atari game Ms. Pacman.
|
|
39.
|
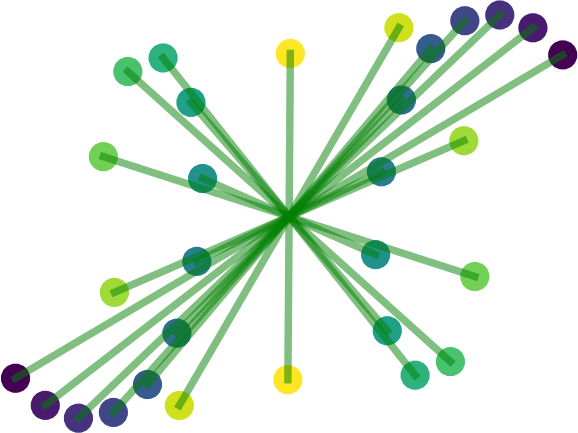 Aligning Time Series on Incomparable Spaces abstractcodeslides
Aligning Time Series on Incomparable Spaces abstractcodeslides
Samuel Cohen, Giulia Luise, Alexander Terenin, Brandon Amos, and Marc Peter Deisenroth
AISTATS 2021
Dynamic time warping (DTW) is a useful method for aligning, comparing
and combining time series, but it requires them to
live in comparable spaces. In this work, we consider
a setting in which time series live on different
spaces without a sensible ground metric, causing DTW
to become ill-defined. To alleviate this, we propose
Gromov dynamic time warping (GDTW), a distance
between time series on potentially incomparable
spaces that avoids the comparability requirement by
instead considering intra-relational geometry. We
derive a Frank-Wolfe algorithm for computing it and
demonstrate its effectiveness at aligning, combining
and comparing time series living on incomparable
spaces. We further propose a smoothed version of
GDTW as a differentiable loss and assess its
properties in a variety of settings, including
barycentric averaging, generative modeling and
imitation learning.
|
|
40.
|
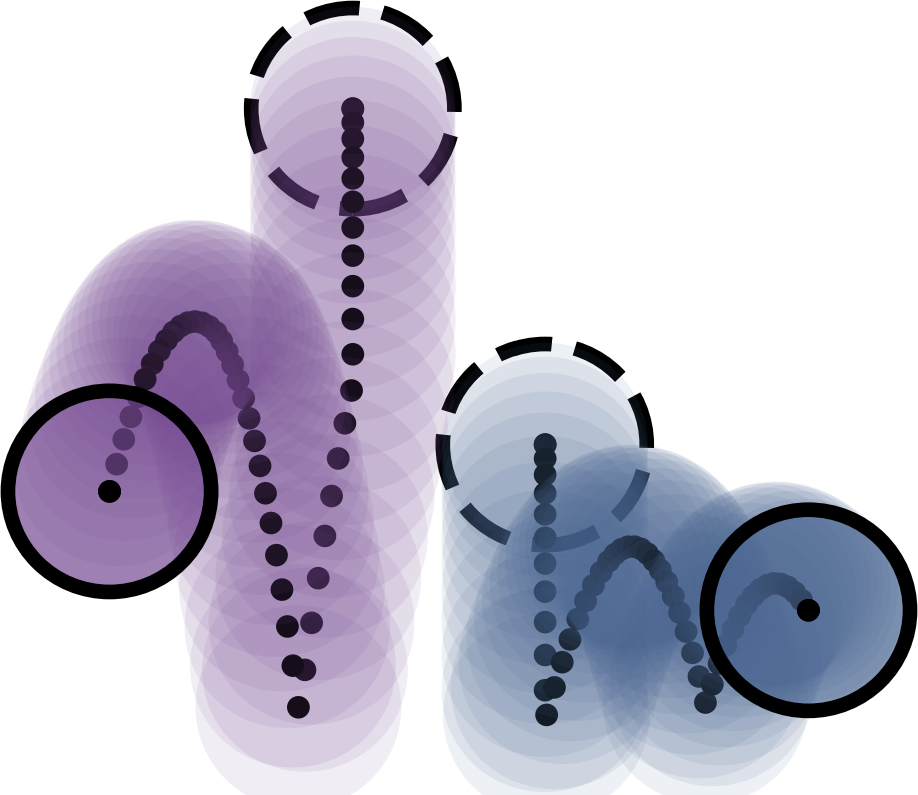 Learning Neural Event Functions for Ordinary Differential Equations abstractcode
Learning Neural Event Functions for Ordinary Differential Equations abstractcode
Ricky T. Q. Chen, Brandon Amos, and Maximilian Nickel
ICLR 2021
The existing Neural ODE formulation relies on an explicit
knowledge of the termination time. We extend Neural
ODEs to implicitly defined termination criteria
modeled by neural event functions, which can be
chained together and differentiated through. Neural
Event ODEs are capable of modeling discrete
(instantaneous) changes in a continuous-time system, without prior knowledge of when these changes should
occur or how many such changes should exist. We test
our approach in modeling hybrid discrete- and
continuous- systems such as switching dynamical
systems and collision in multi-body systems, and we
propose simulation-based training of point processes
with applications in discrete control.
|
|
41.
|
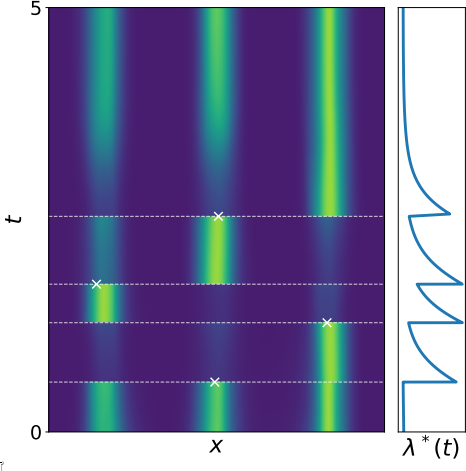 Neural Spatio-Temporal Point Processes abstractcode
Neural Spatio-Temporal Point Processes abstractcode
Ricky T. Q. Chen, Brandon Amos, and Maximilian Nickel
ICLR 2021
We propose a new class of parameterizations for spatio-temporal
point processes which leverage Neural ODEs as a
computational method and enable flexible, high-fidelity models of discrete events that are
localized in continuous time and space. Central to
our approach is a combination of recurrent
continuous-time neural networks with two novel
neural architectures, i.e., Jump and Attentive
Continuous-time Normalizing Flows. This approach
allows us to learn complex distributions for both
the spatial and temporal domain and to condition
non-trivially on the observed event history. We
validate our models on data sets from a wide variety
of contexts such as seismology, epidemiology, urban
mobility, and neuroscience.
|
|
42.
|
Improving Sample Efficiency in Model-Free Reinforcement Learning from Images abstractcode
Denis Yarats, Amy Zhang, Ilya Kostrikov, Brandon Amos, Joelle Pineau, and Rob Fergus
AAAI 2021
Training an agent to solve control tasks directly from
high-dimensional images with model-free
reinforcement learning (RL) has proven
difficult. The agent needs to learn a latent
representation together with a control policy to
perform the task. Fitting a high-capacity encoder
using a scarce reward signal is not only sample
inefficient, but also prone to suboptimal
convergence. Two ways to improve sample efficiency
are to extract relevant features for the task and
use off-policy algorithms. We dissect various
approaches of learning good latent features, and
conclude that the image reconstruction loss is the
essential ingredient that enables efficient and
stable representation learning in image-based
RL. Following these findings, we devise an
off-policy actor-critic algorithm with an auxiliary
decoder that trains end-to-end and matches
state-of-the-art performance across both model-free
and model-based algorithms on many challenging
control tasks. We release our code to encourage
future research on image-based RL.
|
|
43.
|
Neural Fixed-Point Acceleration for Convex Optimization abstractcode
Shobha Venkataraman* and Brandon Amos*
ICML AutoML Workshop 2021
Fixed-point iterations are at the heart of numerical computing and
are often a computational bottleneck in real-time
applications that typically need a fast solution of
moderate accuracy. We present neural fixed-point
acceleration which combines ideas from meta-learning
and classical acceleration methods to automatically
learn to accelerate fixed-point problems that are
drawn from a distribution. We apply our framework to
SCS, the state-of-the-art solver for convex cone
programming, and design models and loss functions to
overcome the challenges of learning over unrolled
optimization and acceleration instabilities. Our
work brings neural acceleration into any
optimization problem expressible with CVXPY.
|
|
44.
|
Sliced Multi-Marginal Optimal Transport abstract
Samuel Cohen, Alexander Terenin, Yannik Pitcan, Brandon Amos, Marc Peter Deisenroth, and K S Sesh Kumar
NeurIPS OTML Workshop 2021
Multi-marginal optimal transport enables one to compare multiple
probability measures, which increasingly finds
application in multi-task learning problems. One
practical limitation of multi-marginal transport is
computational scalability in the number of measures, samples and dimensionality. In this work, we propose
a multi-marginal optimal transport paradigm based on
random one-dimensional projections, whose
(generalized) distance we term the sliced
multi-marginal Wasserstein distance. To construct
this distance, we introduce a characterization of
the one-dimensional multi-marginal Kantorovich
problem and use it to highlight a number of
properties of the sliced multi-marginal Wasserstein
distance. In particular, we show that (i) the sliced
multi-marginal Wasserstein distance is a
(generalized) metric that induces the same topology
as the standard Wasserstein distance, (ii) it admits
a dimension-free sample complexity, (iii) it is
tightly connected with the problem of barycentric
averaging under the sliced-Wasserstein metric. We
conclude by illustrating the sliced multi-marginal
Wasserstein on multi-task density estimation and
multi-dynamics reinforcement learning problems.
|
|
45.
|
Input Convex Gradient Networks abstract
Jack Richter-Powell, Jonathan Lorraine, and Brandon Amos
NeurIPS OTML Workshop 2021
|
|
46.
|
Imitation Learning from Pixel Observations for Continuous Control abstract
Samuel Cohen, Brandon Amos, Marc Peter Deisenroth, Mikael Henaff, Eugene Vinitsky, and Denis Yarats
NeurIPS DeepRL Workshop 2021
We study imitation learning from visual observations only for
controlling dynamical systems with continuous states
and actions. This setting is attractive due to the
large amount of video data available from which
agents could learn from. However, it is challenging
due to i) not observing the actions and ii) the
high-dimensional visual space. In this setting, we
explore recipes for imitation learning based on
adversarial learning and optimal transport. These
recipes enable us to scale these methods to attain
expert-level performance on visual continuous
control tasks in the DeepMind control suite. We
investigate the tradeoffs of these approaches and
present a comprehensive evaluation of the key design
choices. To encourage reproducible research in this
area, we provide an easy-to-use implementation for
benchmarking visual imitation learning, including
our methods and expert demonstrations.
|
|
47.
|
MBRL-Lib: A Modular Library for Model-based Reinforcement Learning abstractcode
Luis Pineda, Brandon Amos, Amy Zhang, Nathan Lambert, and Roberto Calandra
arXiv 2021
Model-based reinforcement learning is a compelling framework for
data-efficient learning of agents that interact with
the world. This family of algorithms has many
subcomponents that need to be carefully selected and
tuned. As a result the entry-bar for researchers to
approach the field and to deploy it in real-world
tasks can be daunting. In this paper, we present
MBRL-Lib–a machine learning library for
model-based reinforcement learning in continuous
state-action spaces based on PyTorch. MBRL-Lib is
designed as a platform for both researchers, to
easily develop, debug and compare new algorithms, and non-expert user, to lower the entry-bar of
deploying state-of-the-art algorithms.
|
|
48.
|
The Differentiable Cross-Entropy Method abstractcodeslides
Brandon Amos and Denis Yarats
ICML 2020
We study the Cross-Entropy Method (CEM) for the non-convex
optimization of a continuous and parameterized
objective function and introduce a differentiable
variant (DCEM) that enables us to differentiate the
output of CEM with respect to the objective
function’s parameters. In the machine learning
setting this brings CEM inside of the end-to-end
learning pipeline where this has otherwise been
impossible. We show applications in a synthetic
energy-based structured prediction task and in
non-convex continuous control. In the control
setting we show on the simulated cheetah and walker
tasks that we can embed their optimal action
sequences with DCEM and then use policy optimization
to fine-tune components of the controller as a step
towards combining model-based and model-free RL.
|
|
49.
|
Objective Mismatch in Model-based Reinforcement Learning abstract
Nathan Lambert, Brandon Amos, Omry Yadan, and Roberto Calandra
L4DC 2020
Model-based reinforcement learning (MBRL) has been shown to be a powerful framework for data-efficiently learning control of continuous tasks. Recent work in MBRL has mostly focused on using more advanced function approximators and planning schemes, with little development of the general framework. In this paper, we identify a fundamental issue of the standard MBRL framework–what we call the objective mismatch issue. Objective mismatch arises when one objective is optimized in the hope that a second, often uncorrelated, metric will also be optimized. In the context of MBRL, we characterize the objective mismatch between training the forward dynamics model with respect to the likelihood of the one-step ahead prediction, and the overall goal of improving performance on a downstream control task. For example, this issue can emerge with the realization that dynamics models effective for a specific task do not necessarily need to be globally accurate, and vice versa globally accurate models might not be sufficiently accurate locally to obtain good control performance on a specific task. In our experiments, we study this objective mismatch issue and demonstrate that the likelihood of one-step ahead predictions is not always correlated with control performance. This observation highlights a critical limitation in the MBRL framework which will require further research to be fully understood and addressed. We propose an initial method to mitigate the mismatch issue by re-weighting dynamics model training. Building on it, we conclude with a discussion about other potential directions of research for addressing this issue.
|
|
50.
|
QNSTOP: Quasi-Newton Algorithm for Stochastic Optimization abstractcode
Brandon Amos, David Easterling, Layne T. Watson, William Thacker, Brent Castle, and Michael Trosset
ACM TOMS 2020
QNSTOP consists of serial and parallel (OpenMP) Fortran 2003 codes for the
quasi-Newton stochastic optimization method of Castle and Trosset. For
stochastic problems, convergence theory exists for the particular
algorithmic choices and parameter values used in QNSTOP. Both the parallel
driver subroutine, which offers several parallel decomposition strategies, and the serial driver subroutine can be used for stochastic optimization or
deterministic global optimization, based on an input switch. QNSTOP is
particularly effective for “noisy” deterministic problems, using only
objective function values. Some performance data for computational systems
biology problems is given.
|
|
51.
|
 Neural Potts Model abstract
Neural Potts Model abstract
Tom Sercu, Robert Verkuil, Joshua Meier, Brandon Amos, Zeming Lin, Caroline Chen, Jason Liu, Yann LeCun, and Alexander Rives
MLCB 2020
We propose the Neural Potts Model objective as an amortized
optimization problem. The objective enables training
a single model with shared parameters to explicitly
model energy landscapes across multiple protein
families. Given a protein sequence as input, the
model is trained to predict a pairwise coupling
matrix for a Potts model energy function describing
the local evolutionary landscape of the
sequence. Couplings can be predicted for novel
sequences. A controlled ablation experiment
assessing unsupervised contact prediction on sets of
related protein families finds a gain from
amortization for low-depth multiple sequence
alignments; the result is then confirmed on a
database with broad coverage of protein sequences.
|
|
52.
|
 Deep Riemannian Manifold Learning abstract
Deep Riemannian Manifold Learning abstract
Aaron Lou, Maximilian Nickel, and Brandon Amos
NeurIPS Geo4dl Workshop 2020
We present a new class of learnable Riemannian manifolds with a metric
parameterized by a deep neural network. The core manifold operations–specifically
the Riemannian exponential and logarithmic maps–are solved using approximate
numerical techniques. Input and parameter gradients are computed with an
adjoint sensitivity analysis. This enables us to fit geodesics and distances with
gradient-based optimization of both on-manifold values and the manifold itself.
We demonstrate our method’s capability to model smooth, flexible metric structures
in graph embedding tasks.
|
|
53.
|
Differentiable Optimization-Based Modeling for Machine Learning abstractcode
Brandon Amos
Ph.D. Thesis 2019
Domain-specific modeling priors and specialized components are becoming
increasingly important to the machine learning field. These components integrate specialized knowledge that we have as humans into model. We argue in
this thesis that optimization methods provide an expressive set of operations
that should be part of the machine learning practitioner’s modeling toolbox.
We present two foundational approaches for optimization-based modeling:
1) the OptNet architecture that integrates optimization problems as individual
layers in larger end-to-end trainable deep networks, and 2) the input-convex
neural network (ICNN) architecture that helps make inference and learning in
deep energy-based models and structured prediction more tractable.
We then show how to use the OptNet approach 1) as a way of combining
model-free and model-based reinforcement learning and 2) for top-k learning
problems. We conclude by showing how to differentiate cone programs and turn
the cvxpy domain specific language into a differentiable optimization layer that
enables rapid prototyping of the approaches in this thesis.
|
|
54.
|
Differentiable Convex Optimization Layers abstractcode
Akshay Agrawal*, Brandon Amos*, Shane Barratt*, Stephen Boyd*, Steven Diamond*, and J. Zico Kolter*
NeurIPS 2019
Recent work has shown how to embed differentiable optimization problems (that is, problems whose solutions can be backpropagated through) as layers within deep learning architectures. This method provides a useful inductive bias for certain problems, but existing software for differentiable optimization layers is rigid and difficult to apply to new settings. In this paper, we propose an approach to differentiating through disciplined convex programs, a subclass of convex optimization problems used by domain-specific languages (DSLs) for convex optimization. We introduce disciplined parametrized programming, a subset of disciplined convex programming, and we show that every disciplined parametrized program can be represented as the composition of an affine map from parameters to problem data, a solver, and an affine map from the solver’s solution to a solution of the original problem (a new form we refer to as affine-solver-affine form). We then demonstrate how to efficiently differentiate through each of these components, allowing for end-to-end analytical differentiation through the entire convex program. We implement our methodology in version 1.1 of CVXPY, a popular Python-embedded DSL for convex optimization, and additionally implement differentiable layers for disciplined convex programs in PyTorch and TensorFlow 2.0. Our implementation significantly lowers the barrier to using convex optimization problems in differentiable programs. We present applications in linear machine learning models and in stochastic control, and we show that our layer is competitive (in execution time) compared to specialized differentiable solvers from past work.
|
|
55.
|
 The Limited Multi-Label Projection Layer abstractcode
The Limited Multi-Label Projection Layer abstractcode
Brandon Amos, Vladlen Koltun, and J. Zico Kolter
arXiv 2019
We propose the Limited Multi-Label (LML) projection layer as a new
primitive operation for end-to-end learning systems. The LML layer
provides a probabilistic way of modeling multi-label predictions
limited to having exactly k labels. We derive efficient forward and
backward passes for this layer and show how the layer can be used to
optimize the top-k recall for multi-label tasks with incomplete label
information. We evaluate LML layers on top-k CIFAR-100 classification
and scene graph generation. We show that LML layers add a negligible
amount of computational overhead, strictly improve the model’s
representational capacity, and improve accuracy. We also revisit the
truncated top-k entropy method as a competitive baseline for top-k
classification.
|
|
56.
|
Generalized Inner Loop Meta-Learning abstractcode
Edward Grefenstette, Brandon Amos, Denis Yarats, Phu Mon Htut, Artem Molchanov, Franziska Meier, Douwe Kiela, Kyunghyun Cho, and Soumith Chintala
arXiv 2019
Many (but not all) approaches self-qualifying as “meta-learning” in
deep learning and reinforcement learning fit a
common pattern of approximating the solution to a
nested optimization problem. In this paper, we give
a formalization of this shared pattern, which we
call GIMLI, prove its general requirements, and
derive a general-purpose algorithm for implementing
similar approaches. Based on this analysis and
algorithm, we describe a library of our design, higher, which we share with the community to assist
and enable future research into these kinds of
meta-learning approaches. We end the paper by
showcasing the practical applications of this
framework and library through illustrative
experiments and ablation studies which they
facilitate.
|
|
57.
|
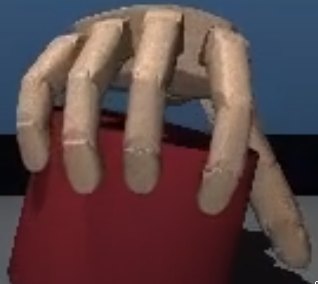 Learning Awareness Models abstract
Learning Awareness Models abstract
Brandon Amos, Laurent Dinh, Serkan Cabi, Thomas Rothörl, Sergio Gómez Colmenarejo, Alistair Muldal, Tom Erez, Yuval Tassa, Nando de Freitas, and Misha Denil
ICLR 2018
We consider the setting of an agent with a fixed body interacting with an
unknown and uncertain external world. We show that models
trained to predict proprioceptive information about the
agent’s body come to represent objects in the external world.
In spite of being trained with only internally available
signals, these dynamic body models come to represent external
objects through the necessity of predicting their effects on
the agent’s own body. That is, the model learns holistic
persistent representations of objects in the world, even
though the only training signals are body signals. Our
dynamics model is able to successfully predict distributions
over 132 sensor readings over 100 steps into the future and we
demonstrate that even when the body is no longer in contact
with an object, the latent variables of the dynamics model
continue to represent its shape. We show that active data
collection by maximizing the entropy of predictions about the
body–touch sensors, proprioception and vestibular
information–leads to learning of dynamic models that show
superior performance when used for control. We also collect
data from a real robotic hand and show that the same models
can be used to answer questions about properties of objects in
the real world. Videos with qualitative results of our models
are available here.
|
|
58.
|
Differentiable MPC for End-to-end Planning and Control abstractcode
Brandon Amos, Ivan Dario Jimenez Rodriguez, Jacob Sacks, Byron Boots, and J. Zico Kolter
NeurIPS 2018
In this paper we present foundations for using model predictive control (MPC) as a differentiable policy class in reinforcement learning. Specifically, we differentiate through MPC by using the KKT conditions of the convex approximation at a fixed point of the solver. Using this strategy, we are able to learn the cost and dynamics of a controller via end-to-end learning in a larger system. We empirically show results in an imitation learning setting, demonstrating that we can recover the underlying dynamics and cost more efficiently and reliably than with a generic neural network policy class
|
|
59.
|
Depth-Limited Solving for Imperfect-Information Games abstract
Noam Brown, Tuomas Sandholm, and Brandon Amos
NeurIPS 2018
A fundamental challenge in imperfect-information games is that states do not have well-defined values. As a result, depth-limited search algorithms used in single-agent settings and perfect-information games do not apply. This paper introduces a principled way to conduct depth-limited solving in imperfect-information games by allowing the opponent to choose among a number of strategies for the remainder of the game at the depth limit. Each one of these strategies results in a different set of values for leaf nodes. This forces an agent to be robust to the different strategies an opponent may employ. We demonstrate the effectiveness of this approach by building a master-level heads-up no-limit Texas hold’em poker AI that defeats two prior top agents using only a 4-core CPU and 16 GB of memory. Developing such a powerful agent would have previously required a supercomputer.
|
|
60.
|
Enabling Live Video Analytics with a Scalable and Privacy-Aware Framework abstract
Junjue Wang, Brandon Amos, Anupam Das, Padmanabhan Pillai, Norman Sadeh, and Mahadev Satyanarayanan
ACM TOMM 2018
We show how to build the components of a privacy-aware, live video
analytics ecosystem from the bottom up, starting
with OpenFace, our new open-source face recognition
system that approaches state-of-the-art
accuracy. Integrating OpenFace with interframe
tracking, we build RTFace, a mechanism for
denaturing video streams that selectively blurs
faces according to specified policies at full frame
rates. This enables privacy management for live
video analytics while providing a secure approach
for handling retrospective policy
exceptions. Finally, we present a scalable, privacy-aware architecture for large camera networks
using RTFace and show how it can be an enabler for a
vibrant ecosystem and marketplace of privacy-aware
video streams and analytics services.
|
|
61.
|
OptNet: Differentiable Optimization as a Layer in Neural Networks abstractcodeslides
Brandon Amos and J. Zico Kolter
ICML 2017
This paper presents OptNet, a network architecture that integrates
optimization problems (here, specifically in the form of quadratic programs)
as individual layers in larger end-to-end trainable deep networks.
These layers encode constraints and complex dependencies
between the hidden states that traditional convolutional and
fully-connected layers often cannot capture.
In this paper, we explore the foundations for such an architecture:
we show how techniques from sensitivity analysis, bilevel
optimization, and implicit differentiation can be used to
exactly differentiate through these layers and with respect
to layer parameters;
we develop a highly efficient solver for these layers that exploits fast
GPU-based batch solves within a primal-dual interior point method, and which
provides backpropagation gradients with virtually no additional cost on top of
the solve;
and we highlight the application of these approaches in several problems.
In one notable example, we show that the method is
capable of learning to play mini-Sudoku (4x4) given just input and output games, with no a priori information about the rules of the game;
this highlights the ability of our architecture to learn hard
constraints better than other neural architectures.
|
|
62.
|
Input Convex Neural Networks abstractcodeslides
Brandon Amos, Lei Xu, and J. Zico Kolter
ICML 2017
|
|
63.
|
Task-based End-to-end Model Learning abstractcode
Priya L. Donti, Brandon Amos, and J. Zico Kolter
NeurIPS 2017
As machine learning techniques have become more ubiquitous, it has
become common to see machine learning prediction algorithms operating
within some larger process. However, the criteria by which we train
machine learning algorithms often differ from the ultimate criteria on
which we evaluate them. This paper proposes an end-to-end approach for
learning probabilistic machine learning models within the context of
stochastic programming, in a manner that directly captures the
ultimate task-based objective for which they will be used. We then
present two experimental evaluations of the proposed approach, one as
applied to a generic inventory stock problem and the second to a
real-world electrical grid scheduling task. In both cases, we show
that the proposed approach can outperform both a traditional modeling
approach and a purely black-box policy optimization approach.
|
|
64.
|
Quasi-Newton Stochastic Optimization Algorithm for Parameter Estimation of a Stochastic Model of the Budding Yeast Cell Cycle abstract
Minghan Chen, Brandon Amos, Layne T. Watson, John Tyson, Yang Cao, Cliff Shaffer, Michael Trosset, Cihan Oguz, and Gisella Kakoti
IEEE/ACM TCBB 2017
Parameter estimation in discrete or continuous deterministic cell
cycle models is challenging for several reasons, including the nature of what can be observed, and
the accuracy and quantity of those observations. The
challenge is even greater for stochastic models, where the number of simulations and amount of
empirical data must be even larger to obtain
statistically valid parameter estimates. The two
main contributions of this work are (1) stochastic
model parameter estimation based on directly
matching multivariate probability distributions, and
(2) a new quasi-Newton algorithm class QNSTOP for
stochastic optimization problems. QNSTOP directly
uses the random objective function value samples
rather than creating ensemble statistics. QNSTOP is
used here to directly match empirical and simulated
joint probability distributions rather than matching
summary statistics. Results are given for a current
state-of-the-art stochastic cell cycle model of
budding yeast, whose predictions match well some
summary statistics and one-dimensional distributions
from empirical data, but do not match well the
empirical joint distributions. The nature of the
mismatch provides insight into the weakness in the
stochastic model.
|
|
65.
|
You can teach elephants to dance: agile VM handoff for edge computing abstract
Kiryong Ha, Yoshihisa Abe, Thomas Eiszler, Zhuo Chen, Wenlu Hu, Brandon Amos, Rohit Upadhyaya, Padmanabhan Pillai, and Mahadev Satyanarayanan
SEC 2017
VM handoff enables rapid and transparent placement changes to
executing code in edge computing use cases where the
safety and management attributes of VM encapsulation
are important. This versatile primitive offers the
functionality of classic live migration but is
highly optimized for the edge. Over WAN bandwidths
ranging from 5 to 25 Mbps, VM handoff migrates a
running 8 GB VM in about a minute, with a downtime
of a few tens of seconds. By dynamically adapting to
varying network bandwidth and processing load, VM
handoff is more than an order of magnitude faster
than live migration at those bandwidths.
|
|
66.
|
An Empirical Study of Latency in an Emerging Class of Edge Computing Applications for Wearable Cognitive Assistance abstract
Zhuo Chen, Wenlu Hu, Junjue Wang, Siyan Zhao, Brandon Amos, Guanhang Wu, Kiryong Ha, Khalid Elgazzar, Padmanabhan Pillai, Roberta Klatzky, Daniel Siewiorek, and Mahadev Satyanarayanan
SEC 2017
An emerging class of interactive wearable cognitive assistance
applications is poised to become one of the key
demonstrators of edge computing infrastructure. In
this paper, we design seven such applications and
evaluate their performance in terms of latency
across a range of edge computing configurations, mobile hardware, and wireless networks, including 4G
LTE. We also devise a novel multi-algorithm approach
that leverages temporal locality to reduce
end-to-end latency by 60% to 70%, without
sacrificing accuracy. Finally, we derive target
latencies for our applications, and show that edge
computing is crucial to meeting these targets.
|
|
67.
|
A Scalable and Privacy-Aware IoT Service for Live Video Analytics abstractcode
Junjue Wang, Brandon Amos, Anupam Das, Padmanabhan Pillai, Norman Sadeh, and Mahadev Satyanarayanan
ACM MMSys 2017 (Best Paper)
We present OpenFace, our new open-source face recognition system
that approaches state-of-the-art accuracy. Integrating OpenFace with
inter-frame tracking, we build RTFace, a mechanism for denaturing video
streams that selectively blurs faces according to specified
policies at full frame rates. This enables privacy management for
live video analytics while providing a secure approach for handling
retrospective policy exceptions. Finally, we present a scalable, privacy-aware architecture for large camera networks using RTFace.
|
|
68.
|
OpenFace: A general-purpose face recognition library with mobile applications abstractcode
Brandon Amos, Bartosz Ludwiczuk, and Mahadev Satyanarayanan
CMU 2016
Cameras are becoming ubiquitous in the Internet of Things (IoT) and
can use face recognition technology to improve context. There is a
large accuracy gap between today’s publicly available face recognition
systems and the state-of-the-art private face recognition
systems. This paper presents our OpenFace face recognition library
that bridges this accuracy gap. We show that OpenFace provides
near-human accuracy on the LFW benchmark and present a new
classification benchmark for mobile scenarios. This paper is intended
for non-experts interested in using OpenFace and provides a light
introduction to the deep neural network techniques we use.
We released OpenFace in October 2015 as an open source library under
the Apache 2.0 license. It is available at:
http://cmusatyalab.github.io/openface/
|
|
69.
|
Image Completion with Deep Learning in TensorFlow abstractcode
Brandon Amos
Blog 2016
Content-aware fill is a powerful tool designers and photographers use to fill in unwanted or missing parts of images. Image completion and inpainting are closely related technologies used to fill in missing or corrupted parts of images. There are many ways to do content-aware fill, image completion, and inpainting. In this blog post, I present Raymond Yeh and Chen Chen et al.’s paper “Semantic Image Inpainting with Perceptual and Contextual Losses,” which was just posted on arXiv on July 26, 2016. This paper shows how to use deep learning for image completion with a DCGAN.
|
|
70.
|
Collapsed Variational Inference for Sum-Product Networks abstract
Han Zhao, Tameem Adel, Geoff Gordon, and Brandon Amos
ICML 2016
Sum-Product Networks (SPNs) are probabilistic inference machines that admit
exact inference in linear time in the size of the network. Existing
parameter learning approaches for SPNs are largely based on the maximum
likelihood principle and hence are subject to overfitting compared to
more Bayesian approaches. Exact Bayesian posterior inference for SPNs is
computationally intractable. Both standard variational inference and
posterior sampling for SPNs are computationally infeasible even for
networks of moderate size due to the large number of local latent
variables per instance. In this work, we propose a novel deterministic
collapsed variational inference algorithm for SPNs that is
computationally efficient, easy to implement and at the same time allows
us to incorporate prior information into the optimization formulation.
Extensive experiments show a significant improvement in accuracy compared
with a maximum likelihood based approach.
|
|
71.
|
Quantifying the impact of edge computing on mobile applications abstract
Wenlu Hu, Ying Gao, Kiryong Ha, Junjue Wang, Brandon Amos, Zhuo Chen, Padmanabhan Pillai, and Mahadev Satyanarayanan
ACM SIGOPS 2016
Computational offloading services at the edge of the Internet for
mobile devices are becoming a reality. Using a wide
range of mobile applications, we explore how such
infrastructure improves latency and energy
consumption relative to the cloud. We present
experimental results from WiFi and 4G LTE networks
that confirm substantial wins from edge computing
for highly interactive mobile applications.
|
|
72.
|
Privacy mediators: helping IoT cross the chasm abstract
Nigel Davies, Nina Taft, Mahadev Satyanarayanan, Sarah Clinch, and Brandon Amos
HotMobile 2016
Unease over data privacy will retard consumer acceptance of IoT
deployments. The primary source of discomfort is a lack of user
control over raw data that is streamed directly from sensors to the
cloud. This is a direct consequence of the over-centralization of
today’s cloud-based IoT hub designs. We propose a solution that
interposes a locally-controlled software component called a privacy
mediator on every raw sensor stream. Each mediator is in the same
administrative domain as the sensors whose data is being collected, and dynamically enforces the current privacy policies of the owners
of the sensors or mobile users within the domain. This solution necessitates
a logical point of presence for mediators within the administrative
boundaries of each organization. Such points of presence
are provided by cloudlets, which are small locally-administered data
centers at the edge of the Internet that can support code mobility.
The use of cloudlet-based mediators aligns well with natural personal
and organizational boundaries of trust and responsibility.
|
|
73.
|
Edge Analytics in the Internet of Things abstract
Mahadev Satyanarayanan, Pieter Simoens, Yu Xiao, Padmanabhan Pillai, Zhuo Chen, Kiryong Ha, Wenlu Hu, and Brandon Amos
IEEE Pervasive Computing 2015
High-data-rate sensors, such as video cameras, are becoming ubiquitous in the
Internet of Things. This article describes GigaSight, an Internet-scale
repository of crowd-sourced video content, with strong enforcement of privacy
preferences and access controls. The GigaSight architecture is a federated
system of VM-based cloudlets that perform video analytics at the edge of the
Internet, thus reducing the demand for ingress bandwidth into the cloud.
Denaturing, which is an owner-specific reduction in fidelity of video content
to preserve privacy, is one form of analytics on cloudlets. Content-based
indexing for search is another form of cloudlet-based analytics. This article
is part of a special issue on smart spaces.
|
|
74.
|
Bad Parts: Are Our Manufacturing Systems at Risk of Silent Cyberattacks? abstract
Hamilton Turner, Jules White, Jaime A. Camelio, Christopher Williams, Brandon Amos, and Robert Parker
IEEE Security & Privacy 2015
Recent cyberattacks have highlighted the risk of physical equipment operating
outside designed tolerances to produce catastrophic failures. A related
threat is cyberattacks that change the design and manufacturing of a
machine’s part, such as an automobile brake component, so it no longer
functions properly. These risks stem from the lack of cyber-physical models
to identify ongoing attacks as well as the lack of rigorous application of
known cybersecurity best practices. To protect manufacturing processes in the
future, research will be needed on a number of critical cyber-physical
manufacturing security topics.
|
|
75.
|
Early Implementation Experience with Wearable Cognitive Assistance Applications abstract
Zhuo Chen, Lu Jiang, Wenlu Hu, Kiryong Ha, Brandon Amos, Padmanabhan Pillai, Alex Hauptmann, and Mahadev Satyanarayanan
WearSys 2015
A cognitive assistance application combines a wearable device such
as Google Glass with cloudlet processing to provide step-by-step
guidance on a complex task. In this paper, we focus on user assistance
for narrow and well-defined tasks that require specialized
knowledge and/or skills. We describe proof-of-concept implementations
for four different tasks: assembling 2D Lego models, freehand
sketching, playing ping-pong, and recommending context-relevant
YouTube tutorials. We then reflect on the difficulties we faced in
building these applications, and suggest future research that could
simplify the creation of similar applications.
|
|
76.
|
The Case for Offload Shaping abstract
Wenlu Hu, Brandon Amos, Zhuo Chen, Kiryong Ha, Wolfgang Richter, Padmanabhan Pillai, Benjamin Gilbert, Jan Harkes, and Mahadev Satyanarayanan
HotMobile 2015
When offloading computation from a mobile device, we show
that it can pay to perform additional on-device work in order
to reduce the offloading workload. We call this offload shaping, and demonstrate its application at many different levels
of abstraction using a variety of techniques. We show that
offload shaping can produce significant reduction in resource
demand, with little loss of application-level fidelity
|
|
77.
|
Are Cloudlets Necessary? abstract
Ying Gao, Wenlu Hu, Kiryong Ha, Brandon Amos, Padmanabhan Pillai, and Mahadev Satyanarayanan
CMU 2015
We present experimental results from Wi-Fi and 4G LTE networks to validate the
intuition that low end-to-end latency of cloud services improves application
response time and reduces energy consumption on mobile devices. We focus
specifically on computational offloading as a cloud service. Using a wide
range of applications, and exploring both pre-partitioned and dynamically
partitioned approaches, we demonstrate the importance of low latency for
cloud offload services. We show the best performance is achieved by
offloading to cloudlets, which are small-scale edge-located data centers. Our
results show that cloudlets can improve response times 51% and reduce energy
consumption in a mobile device by up to 42% compared to cloud offload.
|
|
78.
|
Adaptive VM handoff across cloudlets abstract
Kiryong Ha, Yoshihisa Abe, Zhuo Chen, Wenlu Hu, Brandon Amos, Padmanabhan Pillai, and Mahadev Satyanarayanan
CMU 2015
Cloudlet offload is a valuable technique for ensuring low end-to-end latency of
resource-intensive cloud processing for many emerging mobile applications.
This paper examines the impact of user mobility on cloudlet offload, and
shows that even modest user mobility can result in significant network
degradation. We propose VM handoff as a technique for seamlessly transferring
VM-encapsulated execution to a more optimal offload site as users move. Our
approach can perform handoff in roughly a minute even over limited WANs by
adaptively reducing data transferred. We present experimental results to
validate our implementation and to demonstrate effectiveness of adaptation to
changing network conditions and processing capacity
|
|
79.
|
Global Parameter Estimation for a Eukaryotic Cell Cycle Model in Systems Biology abstract
Tricity Andrew, Brandon Amos, David Easterling, Cihan Oguz, William Baumann, John Tyson, and Layne T. Watson
SummerSim 2014
The complicated process by which a yeast cell divides, known as the cell
cycle, has been modeled by a system of 26 nonlinear ordinary differential
equations (ODEs) with 149 parameters. This model captures the chemical
kinetics of the regulatory networks controlling the cell division process
in budding yeast cells. Empirical data is discrete and matched against
discrete inferences (e.g., whether a particular mutant cell lives or dies)
computed from the ODE solution trajectories. The problem of
estimating the ODE parameters to best fit the model to the data is a
149-dimensional global optimization problem attacked by the deterministic
algorithm VTDIRECT95 and by the nondeterministic algorithms differential
evolution, QNSTOP, and simulated annealing, whose performances are
compared.
|
|
80.
|
Applying machine learning classifiers to dynamic Android malware detection at scale abstractcode
Brandon Amos, Hamilton Turner, and Jules White
IWCMC 2013
The widespread adoption and contextually sensitive
nature of smartphone devices has increased concerns over smartphone
malware. Machine learning classifiers are a current method
for detecting malicious applications on smartphone systems. This
paper presents the evaluation of a number of existing classifiers, using a dataset containing thousands of real (i.e. not synthetic)
applications. We also present our STREAM framework, which
was developed to enable rapid large-scale validation of mobile
malware machine learning classifiers.
|
Last updated on June 11, 2026.
